

加速 AI 与 HPC 应用
高带宽、低延迟特性,大幅提升 AI 训练/推理与科学计算效率
新一代片上网络互联架构,精准破解 AI 训练或推理、高性能计算的内存墙与带宽瓶颈,为数据中心、超算集群、云原生算力基础设施提供低时延、高带宽的极致互联支撑,赋能数据中心新未来

以多芯粒互联架构赋能 AI、超算与云数据中心,
为大规模计算场景提供极致互联支撑。

高带宽、低延迟特性,大幅提升 AI 训练/推理与科学计算效率

基于 UCIe 多 Die 互联,可构建数千至数万核心的超大规模计算集群。

模块化设计搭配先进制程,平衡功耗与成本,提升企业投资回报。

作为核心基石,构建面向未来的云原生、数据中心级算力系统。


兼容 CHI.E 协议,支持 16/64/128 等多核多 Die 灵活挂载,采用 1 拍过路由的创新设计
先进互联架构搭载 1.8GHz@12nm 工作频率,实现 < 2ns 点到点延迟,提供 115GB/s 峰值路由带宽
极致低延迟性能基于 UCIe 2.0 设计,支持 2/4 Die 先进封装,提供多规格片间带宽配置与自动化控制
多芯粒互联支持 1/2/4 灵活通道,单 Die 最大 16 通道,支持 KB 级数据块高效多播与 M×N 拓扑定制
高可拓展性搭载创新片上网络(NoC)架构,采用 1 拍过路由设计,以 1.8GHz@12nm 主频实现 < 2ns 低延迟通信,全面兼容 CHI.E 与 UCIe 2.0 协议,支持多芯粒高效互联。

自研片上互联架构,性能、兼容、扩展一把抓
打造超算与 AI 计算全场景互联底座
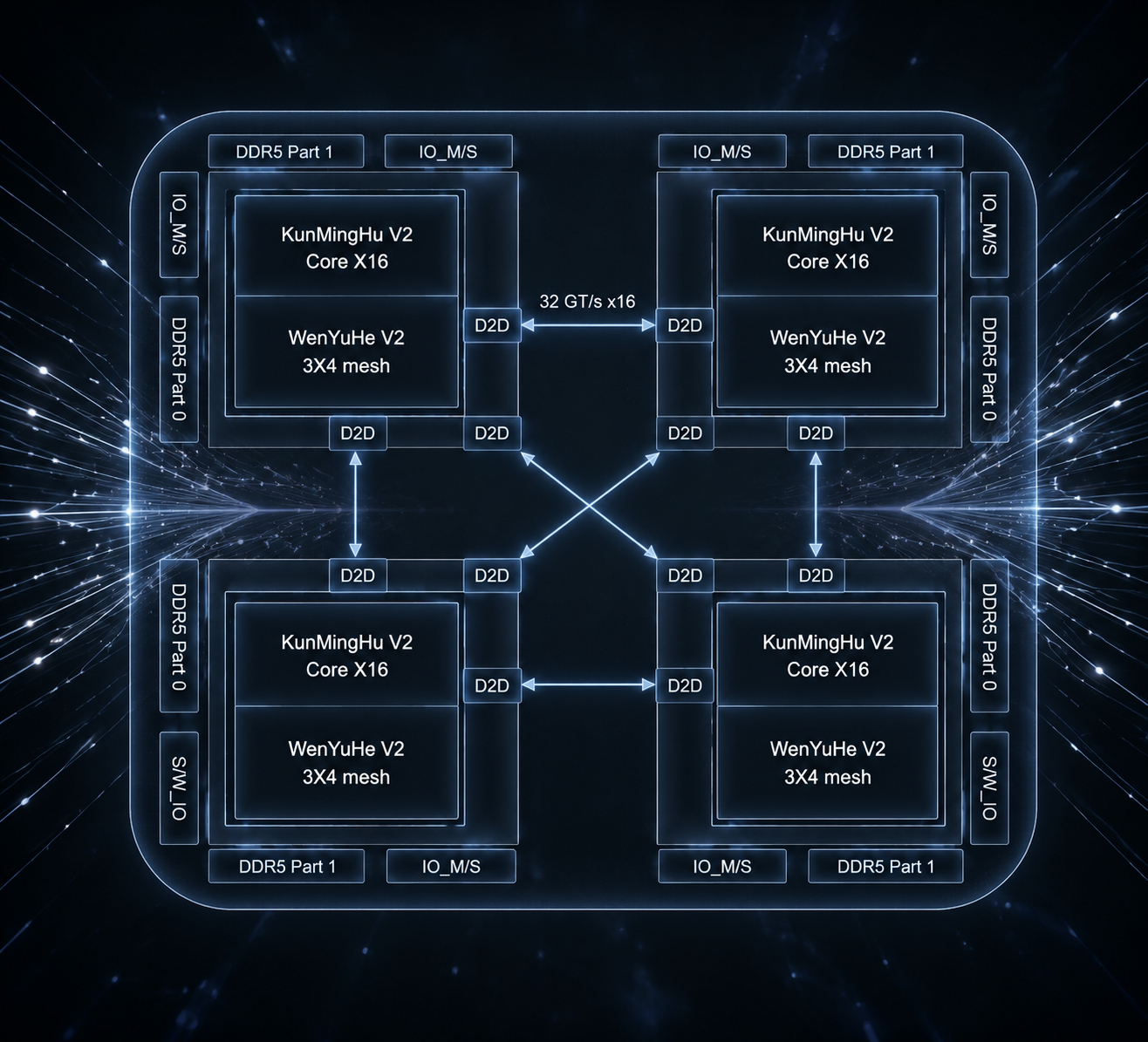
围绕高带宽、低延迟、协议兼容与多芯粒扩展,构建面向大规模计算系统的互联能力。
1.8 GHZ@12nm tt0p8v
115 GB/s@256bit
MxN定制可配
<2ns
>1.8TB/s@8x8

高性能网络互联 NOC 面向 AI 训练、超算集群与云数据中心场景持续演进,以开放源码、开放接口规范与开放社区,连接开发者、研究者与产业伙伴,共同推进高性能片上互联生态走向更广阔的大规模计算场景。

新一代片上网络互联架构,精准破解 AI 训练或推理、高性能计算的内存墙与带宽瓶颈,为数据中心、超算集群、云原生算力基础设施提供低时延、高带宽的极致互联支撑,赋能数据中心新未来
以多芯粒互联架构赋能 AI、超算与云数据中心,
为大规模计算场景提供极致互联支撑。


高带宽、低延迟特性,大幅提升 AI 训练/推理与科学计算效率

基于 UCIe 多 Die 互联,可构建数千至数万核心的超大规模计算集群。

模块化设计搭配先进制程,平衡功耗与成本,提升企业投资回报。

作为核心基石,构建面向未来的云原生、数据中心级算力系统。

兼容 CHI.E 协议,支持 16/64/128 等多核多 Die 灵活挂载,采用 1 拍过路由的创新设计
先进互联架构搭载 1.8GHz@12nm 工作频率,实现 < 2ns 点到点延迟,提供 115GB/s 峰值路由带宽
极致低延迟性能基于 UCIe 2.0 设计,支持 2/4 Die 先进封装,提供多规格片间带宽配置与自动化控制
多芯粒互联支持 1/2/4 灵活通道,单 Die 最大 16 通道,支持 KB 级数据块高效多播与 M×N 拓扑定制
高可拓展性
搭载创新片上网络(NoC)架构,采用 1 拍过路由设计,以 1.8GHz@12nm 主频实现 < 2ns 低延迟通信,全面兼容 CHI.E 与 UCIe 2.0 协议,支持多芯粒高效互联。

自研片上互联架构,性能、兼容、扩展一把抓
打造超算与 AI 计算全场景互联底座
围绕高带宽、低延迟、协议兼容与多芯粒扩展,
构建面向大规模计算系统的互联能力。

1.8 GHZ@12nm tt0p8v
115 GB/s@256bit
MxN定制可配
<2ns
>1.8TB/s@8x8
开源生态
高性能网络互联 NOC 面向 AI 训练、超算集群与云数据中心场景持续演进,以开放源码、开放接口规范与开放社区,连接开发者、研究者与产业伙伴,共同推进高性能片上互联生态走向更广阔的大规模计算场景。










