具身智能-低时延智算核心
通推一体架构与统一内存寻址,兼顾低功耗、高吞吐、低延迟,保障具身智能长期稳定可靠实时运行。

采用统一寻址实现超低时延,依托7nm先进工艺打造高能效与最高 64TOPS/核心(典型配置)强劲算力,以通推同构扩展架构完美适配端云全域场景

面向大模型推理、边缘智能与云端智算场景的优化设计,释放通推一体架构的全栈性能潜力

通推一体架构与统一内存寻址,兼顾低功耗、高吞吐、低延迟,保障具身智能长期稳定可靠实时运行。

兼顾通用计算与本地大模型推理,满足 AIPC 实际需求。配合推测解码等推理技术,提高 AIPC 矩阵算力利用率。

适应旗舰大模型长上下文、MoE 等特性,以可扩展多核架构与软硬协同优化,加速云端推理,助力云端AI业务高效交付。


采用通推同构设计,融合通用计算与AI推理,支持矩阵指令扩展与AI加速向量指令
通推一体架构依托 7nm 先进工艺打造超 64TOPS 算力,搭载专用 AMU 矩阵运算单元与 AI 负载亲和缓存优化
算力配置内置硬件级内存隔离与数据加密,适配大模型推理与云端智算的隐私保护需求
高安全性设计支持核心数量灵活配置,适配 BF16/INT8/FP8/MXFP8/MXFP4 多精度(典型配置),兼容端侧与云端多种部署架构
全域可拓展性搭载通推一体多核同构架构,以AI加速向量指令与专用AI矩阵单元,全面支持 AME 指令规范与统一内存寻址,AI 推理兼顾低时延与高吞吐。

香山自研通推一体架构,性能、能效、兼容一把抓,打造端云全域 AI 算力底座

凭借先进架构与高可扩展性昆明湖V2 具备了从边缘端到高性能计算(HPC)领域的全场景适配能力


微架构与核心设计
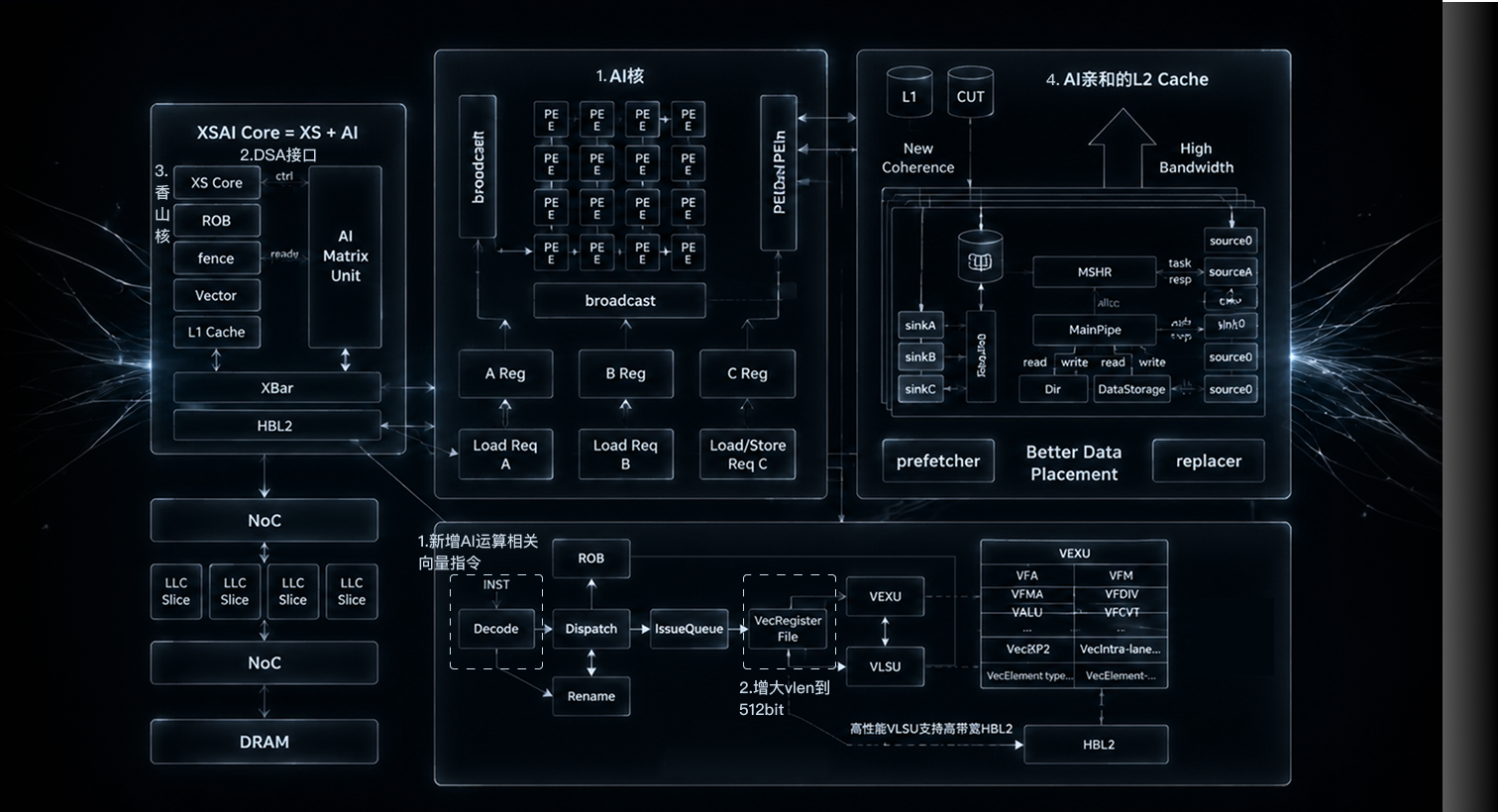
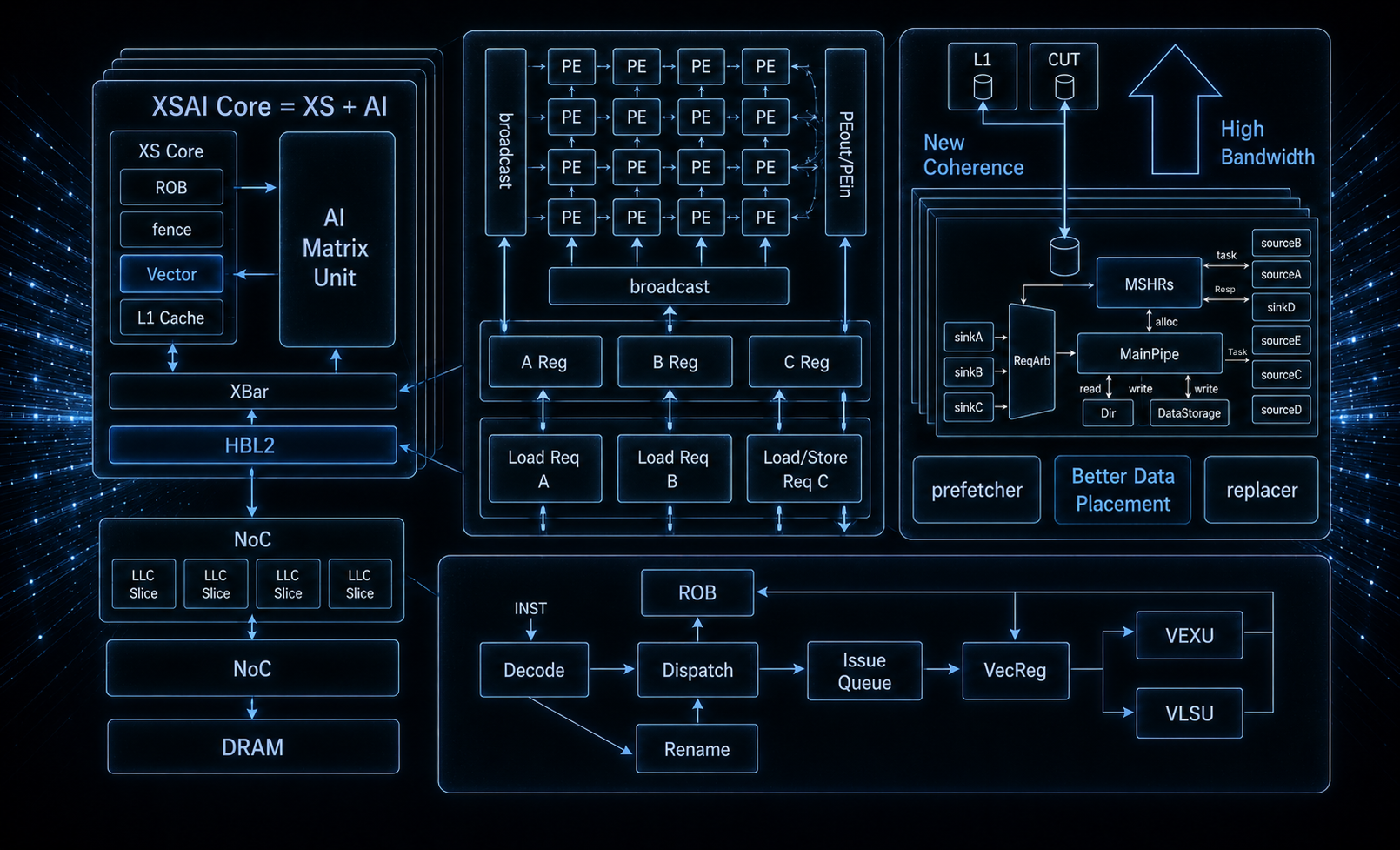
基于自主可控的香山 / 昆明湖 V2 高性能核心打造,为通推一体算力提供坚实架构底座。卓越 AI 算力表现
AI 算力可达 > 64TOPS,依托专用矩阵运算单元,显著提升神经网络计算并行度与吞吐量。指令集与矩阵精度
全面兼容 RISC-V RVA23 最新高性能标准,支持 BF16/INT8/FP8/MXFP8/MXFP4 多精度计算,向量提供特殊指令,加速 AI 应用。专用 AI 硬件加速
内置 AMU 矩阵单元、AI 亲和 L2 Cache,原生支持 AME 矩阵指令与 DSA 接口,深度优化 AI 任务执行效率。核心配置与扩展性
支持多核心灵活扩展,适配边缘端到云端的多场景部署需求。专用 AI 加速架构结合高带宽 L2 Cache,在缓存一致性与数据访问深度优化,充分提升整体算力性能。内置 AI 矩阵运算单元,显著提升神经网络计算并行效率与吞吐性能。
提供统一硬件加速接口标准,简化开发流程并提升生态兼容与易用性。
硬件级原生支持矩阵运算,减少指令转换开销并提升复杂 AI 算法效率。
针对 AI 任务访存特性优化缓存结构,有效降低延迟并提升访问效率。
创新性地将通用 CPU 的指令级灵活性与专用矩阵加速器的高吞吐计算能力深度融合于统一的硬件体系架构之中。
了解开源生态
> 15.0 / GHz (SPECint2006)
香山AI面向具身智能、AIPC与云端智算场景持续演进,
以开放源码、开放 AI 工具链与开放社区,连接开发者、研究者与产业伙伴,共同推进通推一体 AI 生态走向更广阔的端云计算场景。

采用统一寻址实现超低时延,依托7nm先进工艺打造高能效与最高 64TOPS/核心(典型配置)强劲算力,以通推同构扩展架构完美适配端云全域场景
面向大模型推理、边缘智能与云端智算场景的优化设计,释放通推一体架构的全栈性能潜力

通推一体架构与统一内存寻址,兼顾低功耗、高吞吐、低延迟,保障具身智能长期稳定可靠实时运行。
兼顾通用计算与本地大模型推理,满足 AIPC 实际需求。配合推测解码等推理技术,提高 AIPC 矩阵算力利用率。

适应旗舰大模型长上下文、MoE 等特性,以可扩展多核架构与软硬协同优化,加速云端推理,助力云端AI业务高效交付。


采用通推同构设计,融合通用计算与AI推理,支持矩阵指令扩展与AI加速向量指令
通推一体架构依托 7nm 先进工艺打造超 64TOPS 算力,搭载专用 AMU 矩阵运算单元与 AI 负载亲和缓存优化
算力配置内置硬件级内存隔离与数据加密,适配大模型推理与云端智算的隐私保护需求
高安全性设计支持核心数量灵活配置,适配 BF16/INT8/FP8/MXFP8/MXFP4 多精度(典型配置),兼容端侧与云端多种部署架构
全域可拓展性
搭载通推一体多核同构架构,以AI加速向量指令与专用AI矩阵单元,全面支持 AME 指令规范与统一内存寻址,AI 推理兼顾低时延与高吞吐。

香山自研通推一体架构,性能、能效、兼容一把抓,打造端云全域 AI 算力底座
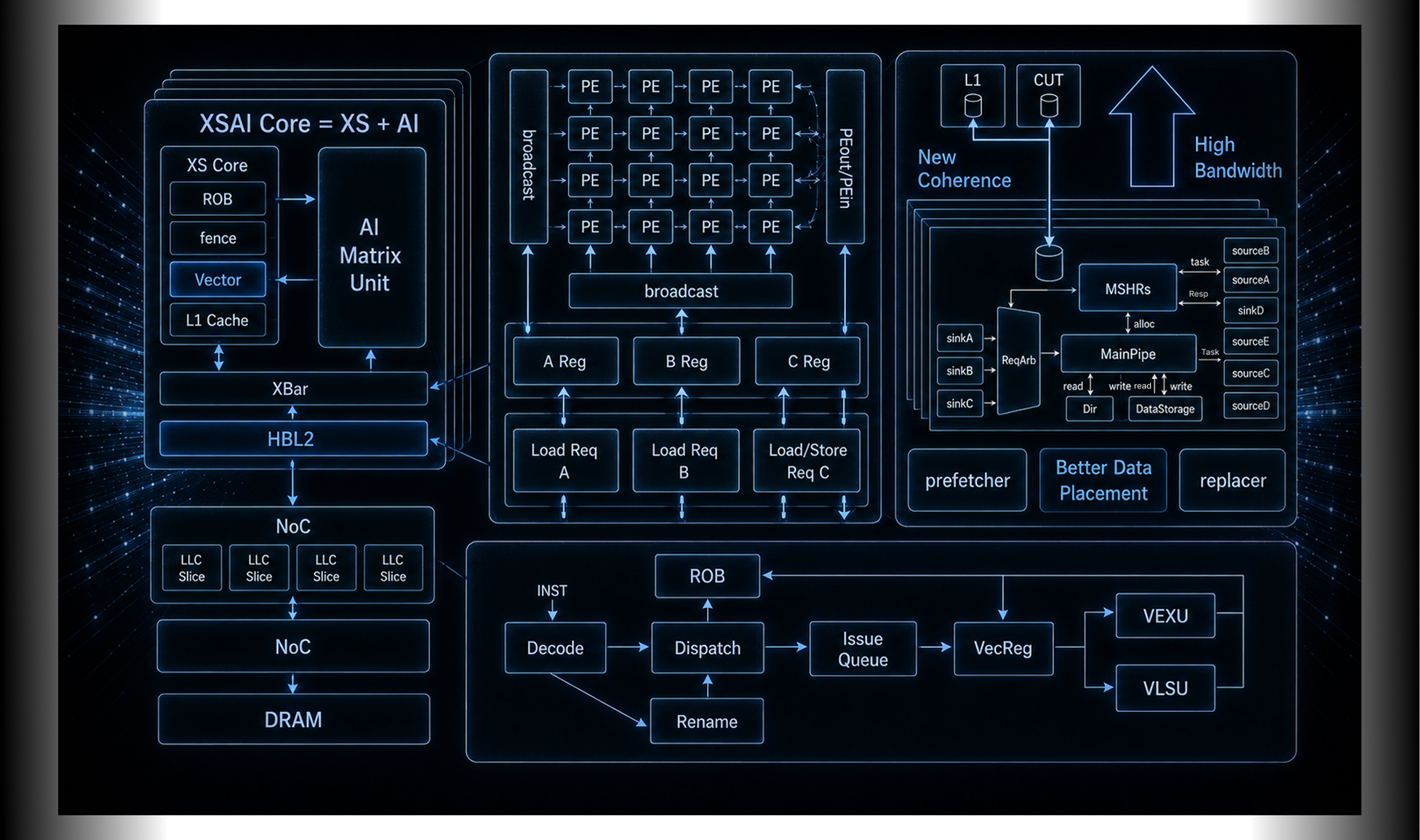
凭借先进架构与高可扩展性
昆明湖V2 具备了从边缘端到高性能计算(HPC)领域的全场景适配能力
基于自主可控的香山 / 昆明湖 V2 高性能核心打造,为通推一体算力提供坚实架构底座。
AI 算力可达 > 64TOPS,依托专用矩阵运算单元,显著提升神经网络计算并行度与吞吐量。
全面兼容 RISC-V RVA23 最新高性能标准,支持 BF16/INT8/FP8/MXFP8/MXFP4 多精度计算,向量提供特殊指令,加速 AI 应用。
内置 AMU 矩阵单元、AI 亲和 L2 Cache,原生支持 AME 矩阵指令与 DSA 接口,深度优化 AI 任务执行效率。
支持多核心灵活扩展,适配边缘端到云端的多场景部署需求。专用 AI 加速架构结合高带宽 L2 Cache,在缓存一致性与数据访问深度优化,充分提升整体算力性能。

内置 AI 矩阵运算单元,显著提升神经网络计算并行效率与吞吐性能。

提供统一硬件加速接口标准,简化开发流程并提升生态兼容与易用性。

硬件级原生支持矩阵运算,减少指令转换开销并提升复杂 AI 算法效率。

针对 AI 任务访存特性优化缓存结构,有效降低延迟并提升访问效率。
创新性地将通用 CPU 的指令级灵活性与专用矩阵加速器的高吞吐计算能力深度融合于统一的硬件体系架构之中。
了解开源生态
> 15.0 / GHz (SPECint2006)
香山AI面向具身智能、AIPC与云端智算场景持续演进,
以开放源码、开放 AI 工具链与开放社区,连接开发者、研究者与产业伙伴,共同推进通推一体 AI 生态走向更广阔的端云计算场景。










